Skill RSI: Recursive Self Improvement for Agent Skills [Free + Open Source]
By Justin Wetch
GITHUB REPO: https://github.com/justinwetch/Skill-RSI
For quick install, paste this into Codex:
Set up Skill RSI from https://github.com/justinwetch/Skill-RSI. Clone the repo, read AGENTS.md, install dependencies, build the UI, configure and install the Codex plugin, run the plugin smoke checks, and tell me when to start a fresh Codex thread. Do not start any model-backed Skill RSI run yet.
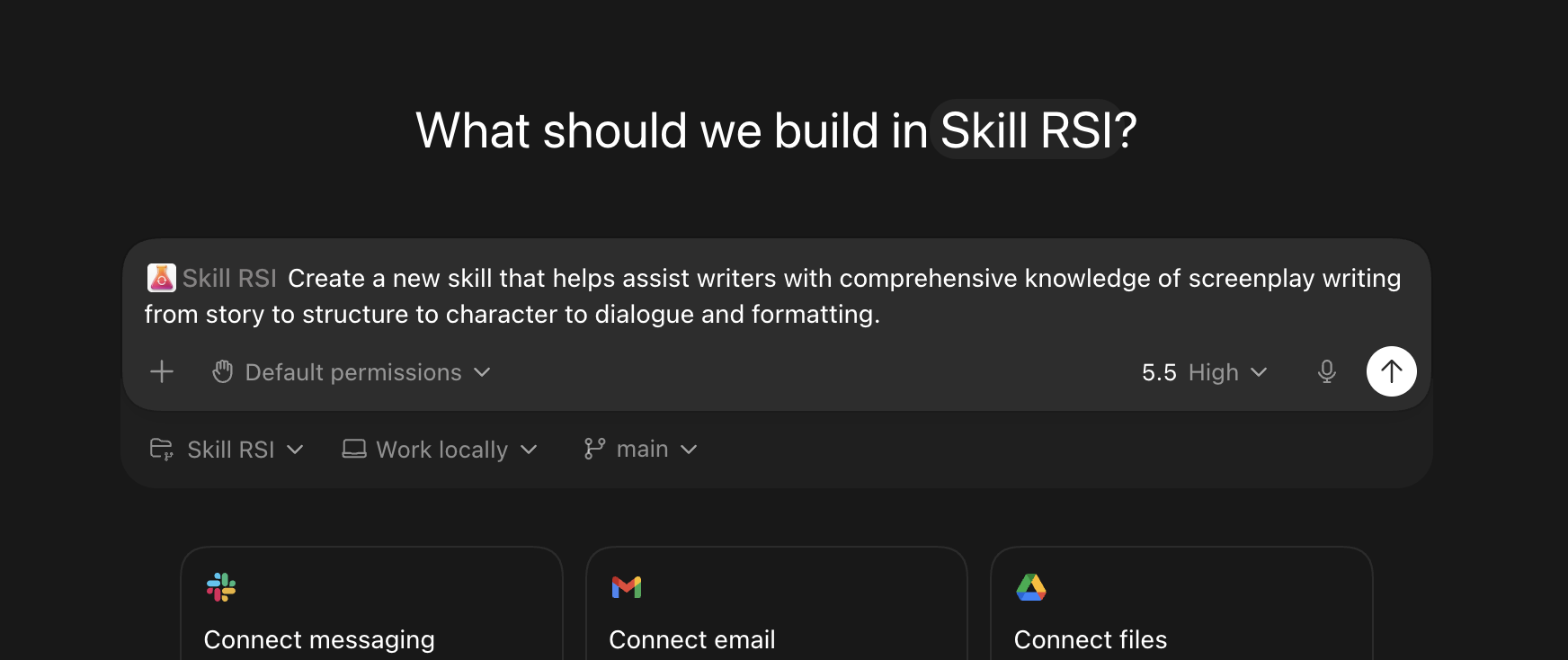
What if a skill could improve itself?
Recursive self-improvement is one of the big ideas in AI right now. You can see the shape of it in projects like Andrej Karpathy’s autoresearch, where an agent changes code, runs a short training experiment, checks whether the metric improved, and repeats. The reason that loop can run is that it has a number to optimize. Training loss goes down or it doesn’t.
A skill is messier.
A skill doesn’t hand you a clean scalar. “Better” is a judgment. A skill can become clearer but less complete, more ambitious but less reliable, sharper on one class of tasks and worse on another. So the hard part isn’t just generating a new version. The hard part is judging the change well enough that you can trust the loop.
That’s what Skill RSI is for.
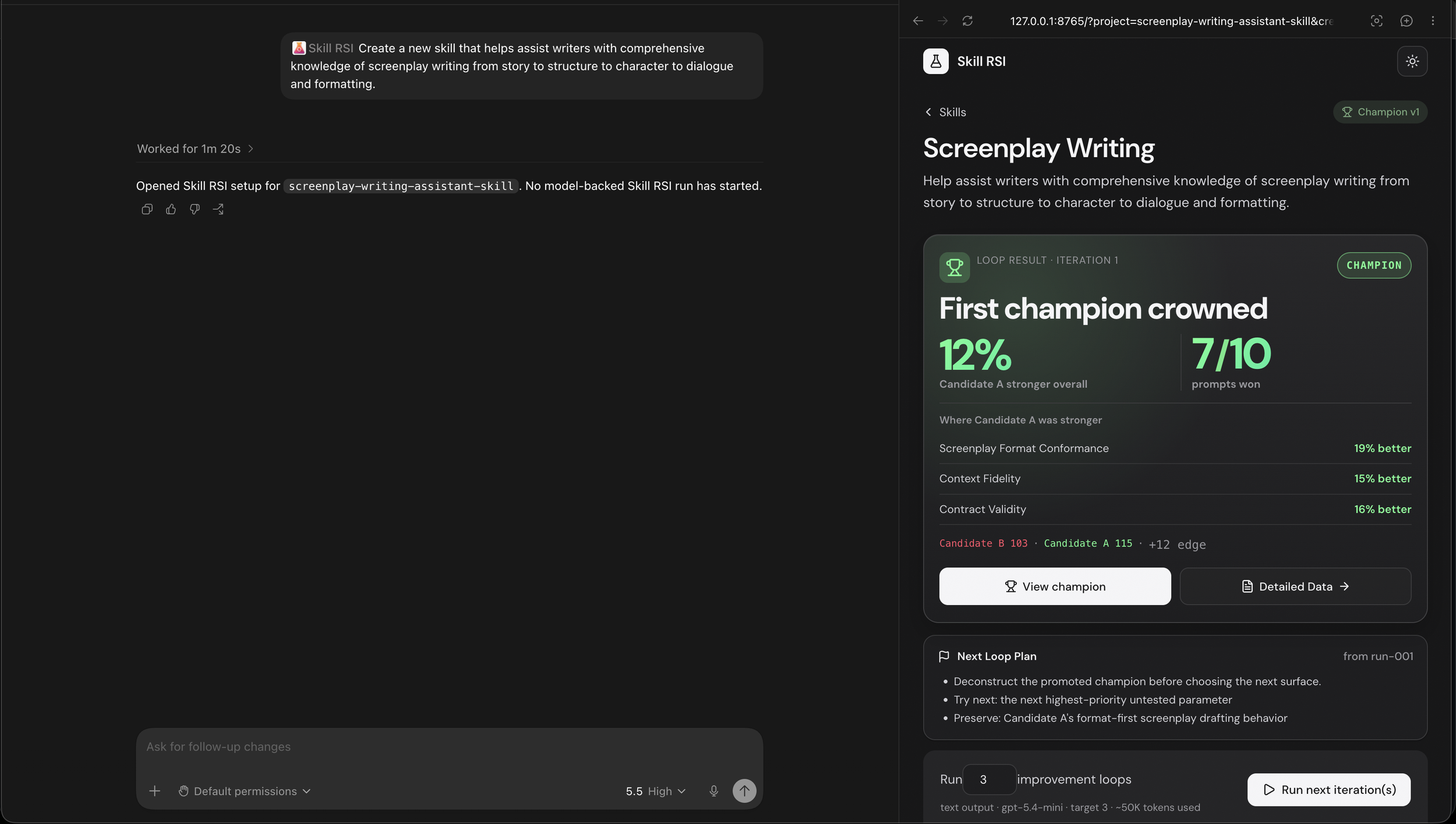
Skill RSI is an agentic system that recursively improves Agent Skills with a controlled, evidence-backed process. You can start from an existing skill, or you can start from scratch with just a goal. You can run a set number of iterations, schedule it, or let hook context queue up for the next run. Then Skill RSI does the work: researches the domain, plans an experiment, builds a challenger, evaluates it against the current champion, and only promotes it if the evidence clears the bar.
Usually recursive self-improvement is a thought experiment.
This one runs on your laptop.
This is the sequel to SkillEval. Earlier this year, I built SkillEval because I had rewritten a frontend design skill and wanted to know whether it was actually better. Not better according to my mood that afternoon, not better because one output looked nice, but better across a spread of prompts and criteria. SkillEval could run a head-to-head between any two versions of a skill and tell you which one won.
That left an obvious next question.
If SkillEval can tell me which version is better, why am I still the one deciding what to try next?
Skill RSI closes that loop.
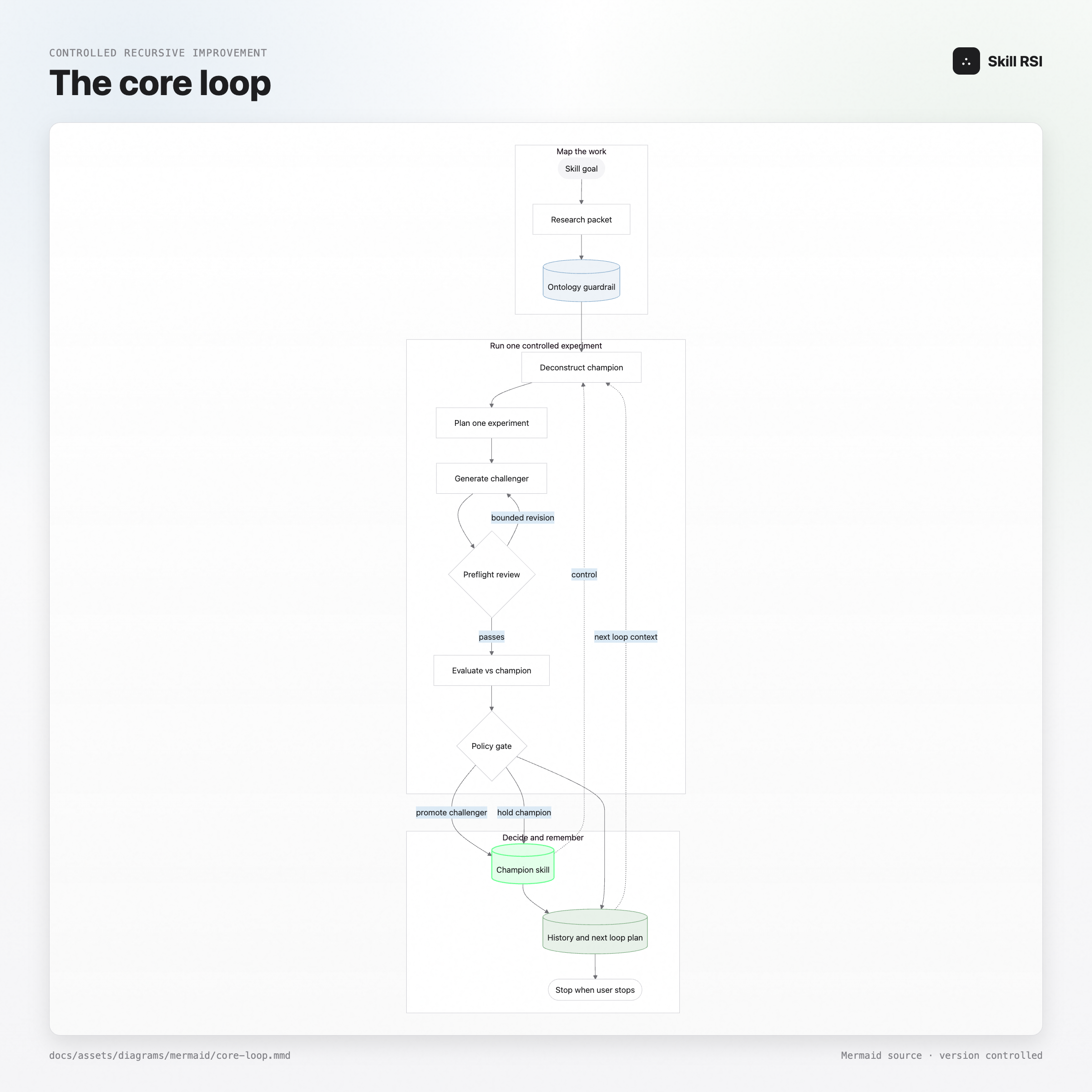
The simplest version is: study the skill, form a theory about what would help, build a variant, test it, keep the winner. Again and again, until you stop it.
The less simple version is where most of the product lives.
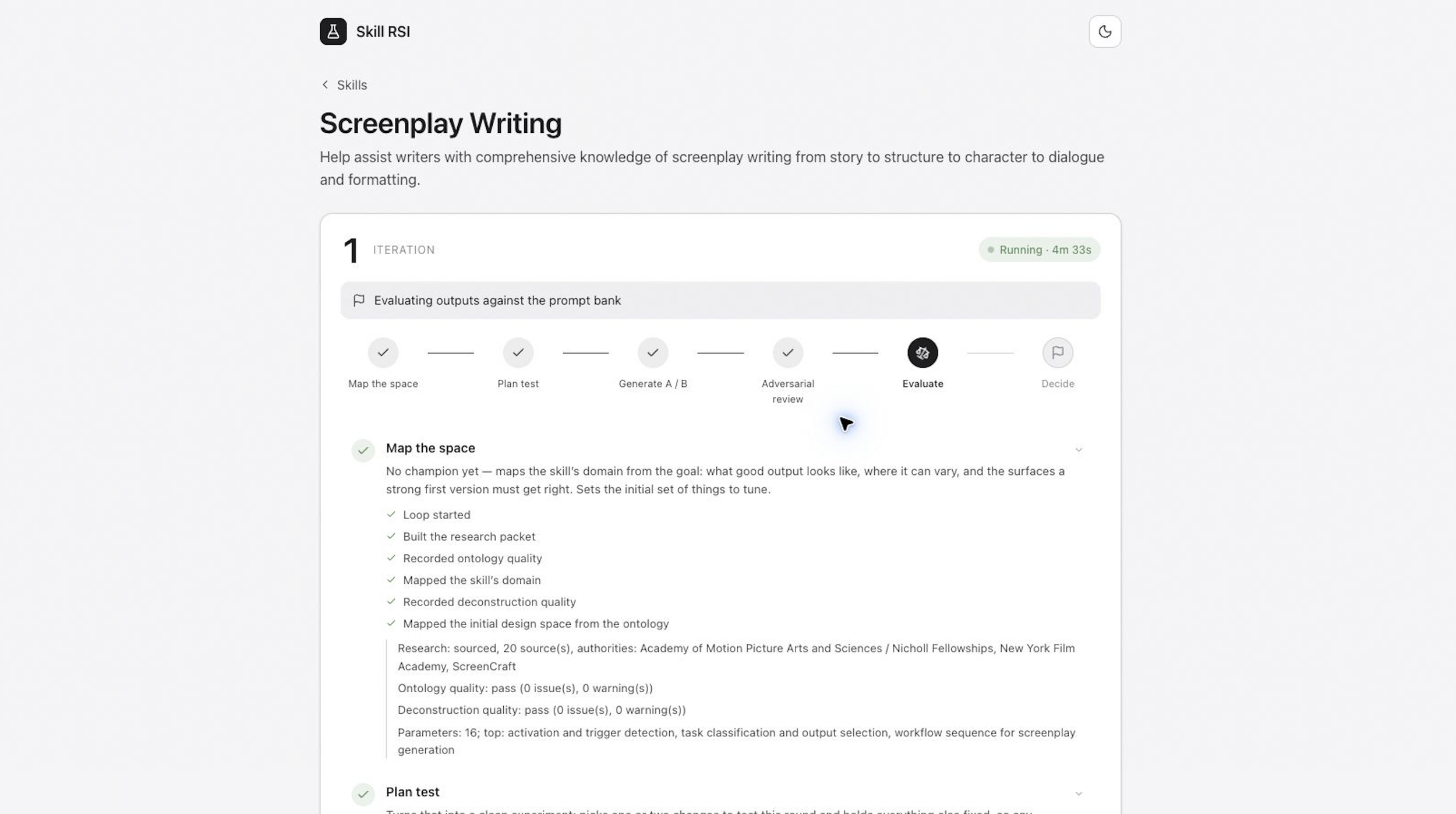
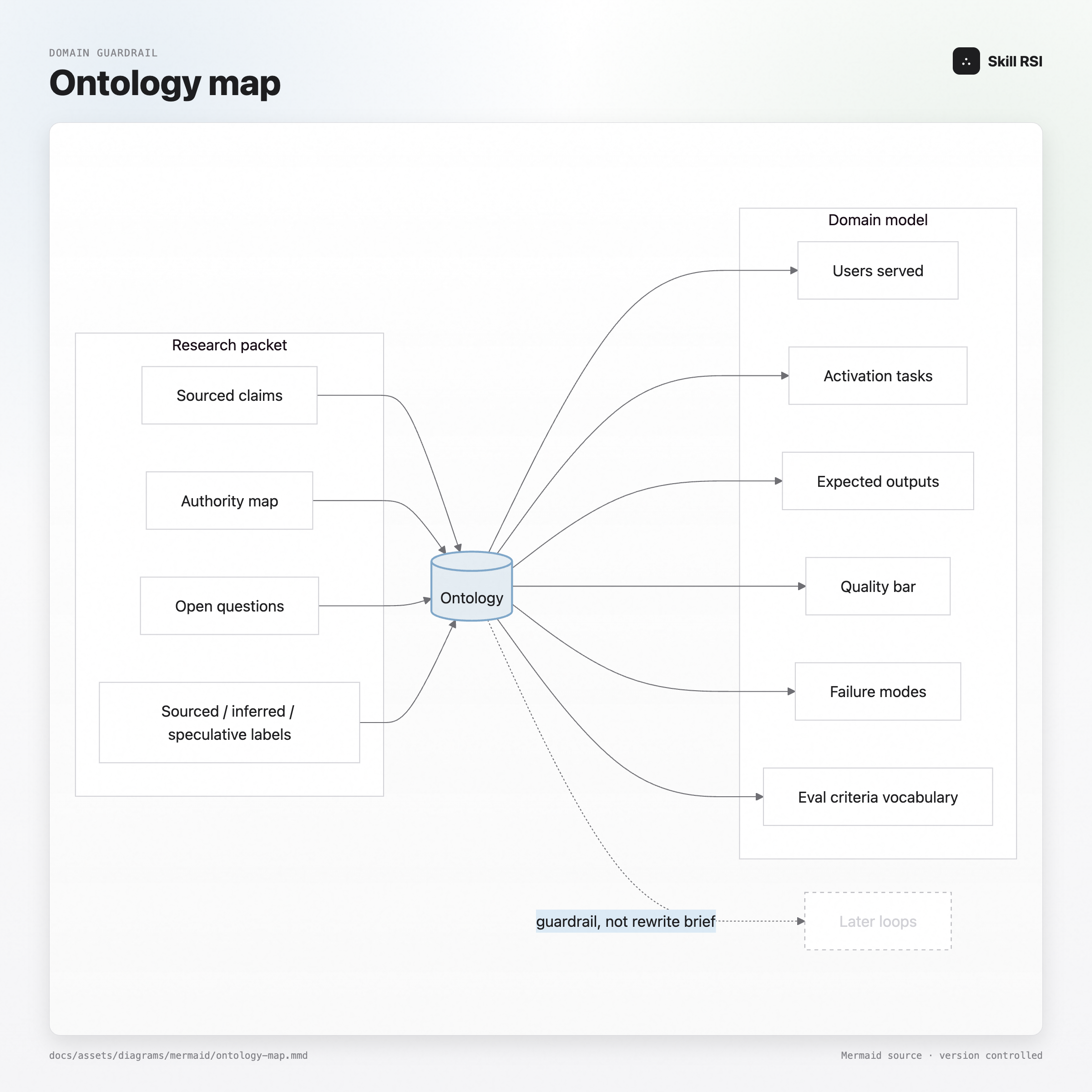
Before Skill RSI writes a single line, it tries to understand the domain the skill is supposed to operate in. This is basically deep research for skills. It builds a research packet, pulls in sourced claims, identifies authorities and strong opinions in the field, tracks open questions and gaps, and turns that into an ontology: a working model of who the skill serves, when it should activate, what excellent output looks like, and which failure modes are worth catching.
The ontology is not a celebrity quote machine. For a product skill, Steve Jobs or Dieter Rams might matter because their taste implies real pressure toward simplicity and restraint. For an accessibility-heavy frontend skill, W3C and WCAG matter because they define concrete expectations. Skill RSI doesn’t blindly follow authorities, but it learns from them where they are useful. The point is to stop pretending that model memory is the same thing as research.
Once there is a champion skill, the system changes posture. It stops trying to invent from zero and starts treating the current skill as an artifact to improve.
Ontology maps the domain. Deconstruction maps the champion.
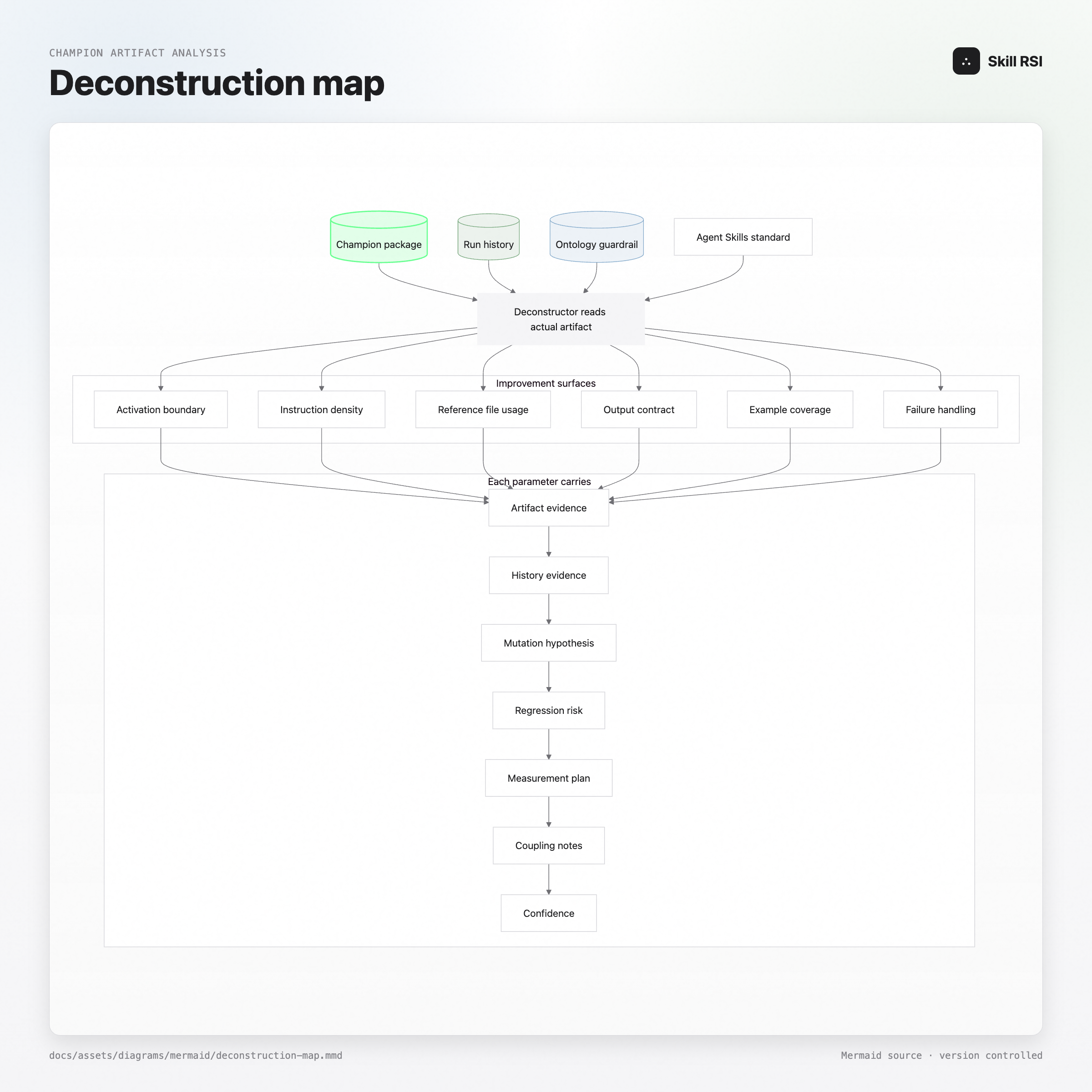
The deconstructor reads the goal, the history, the ontology, the Agent Skills standard, and the full champion package. Then it breaks the skill into testable improvement surfaces. “Make the skill better” is useless. “Increase the density of concrete implementation examples in the output contract section while preserving activation boundaries” is something you can test.
Each surface carries a hypothesis, artifact evidence, history evidence, a regression risk, a measurement plan, coupling notes, and confidence. This matters because without it, recursive improvement turns into a fancy random walk. You get wholesale rewrites that feel productive because files changed, but you don’t know what caused the improvement, and you don’t know what broke.
Skill RSI is built around the opposite discipline.
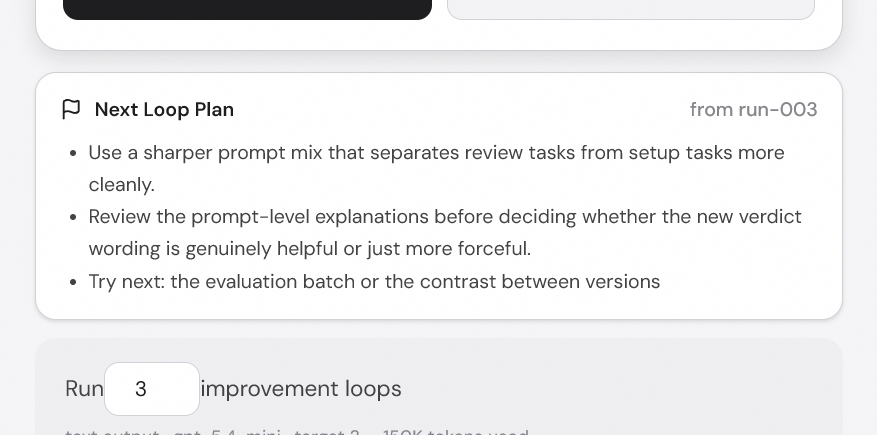
The current champion is the control. The challenger is the treatment. Both run against the same prompts under the same criteria. Most loops move one focused parameter family at a time, so when a challenger wins, you know what won. If it loses, that failure is recorded too, which is almost as valuable. The system keeps a compact history of what changed, what worked, what failed, what not to repeat, and what the next loop should try.
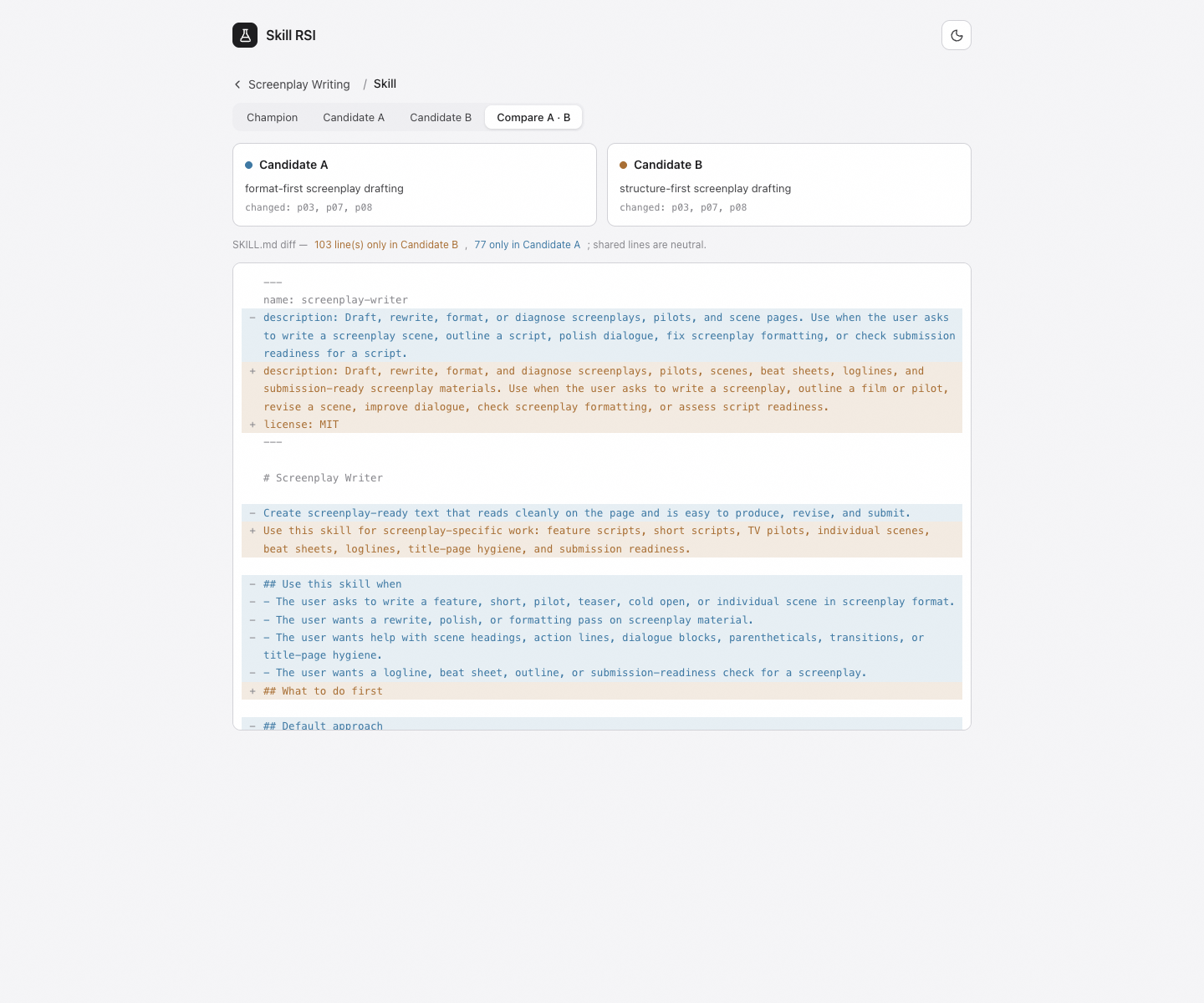
Before a challenger ever reaches evaluation, it goes through adversarial preflight review. The reviewer checks for boring but fatal problems: missing or invalid SKILL.md, broken frontmatter, dropped reference files, unsafe scripts, prompt leakage, strategy drift, or a giant rewrite when the plan called for a local mutation. A malformed candidate should not get a medal for making it to eval. It should stop cleanly and explain what failed.
The evaluation engine is a headless adaptation of SkillEval. Text skills produce written artifacts. Code skills produce runnable code. Code plus visuals skills produce complete browser-renderable code, which Skill RSI renders locally, screenshots, and judges with the visible result included. The prompt bank has memory. Stable prompts protect behavior that already worked. Exploration prompts probe the hypothesis for the current round.
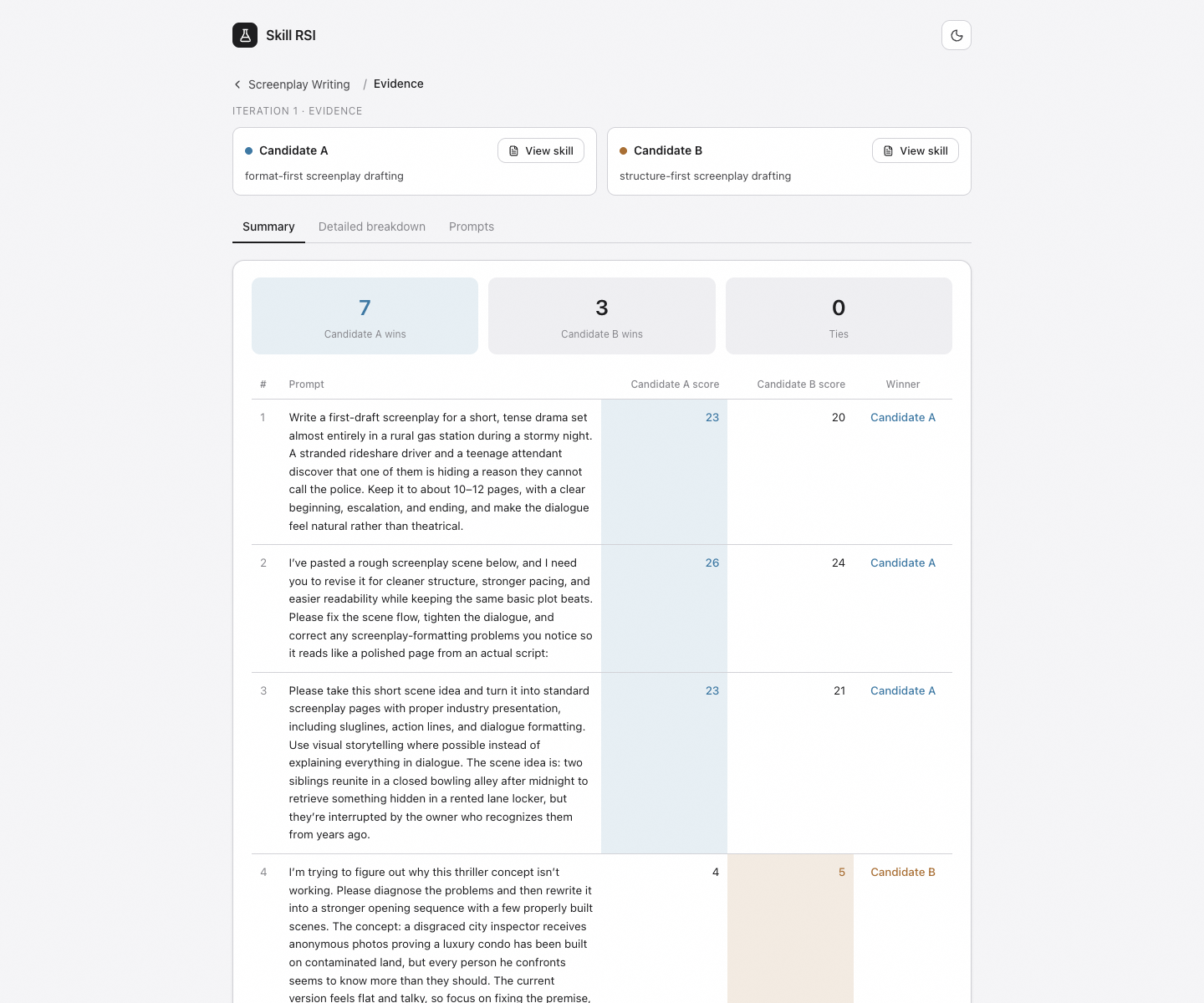
A malformed prompt is a system bug, not a fair test.
Promotion is gated too. The challenger does not become champion just because it won one prompt. It has to clear score and margin thresholds, avoid critical stable-prompt regressions, and complete enough evaluation to make the decision meaningful. The analyst reads the judge reasoning, prompt-level patterns, confidence, noise, and regression risk before recommending a promotion, a rejection, an inconclusive result, or a different experiment direction.
A challenger only gets promoted if it wins by a real margin and breaks nothing that already worked.
That’s the core product: recursive improvement, but with enough bookkeeping and skepticism that the loop doesn’t become vibes wearing a lab coat.
You can inspect all of it. The local UI shows the plan for each round, live progress, detailed eval data, prompt-level evidence, judge rationale, criterion scores, candidate outputs, champion and challenger skill packages, diffs, rendered screenshots when available, and the full improvement history. Every promotion decision links back to the evidence that produced it.
You can run it standalone from the CLI. You can use the local web app. You can also run it as a Codex plugin. In Codex, I can ask for a skill, Skill RSI opens in the sidebar, creates or imports the project, and gives me an operator surface for watching runs, inspecting evidence, and exporting the champion.
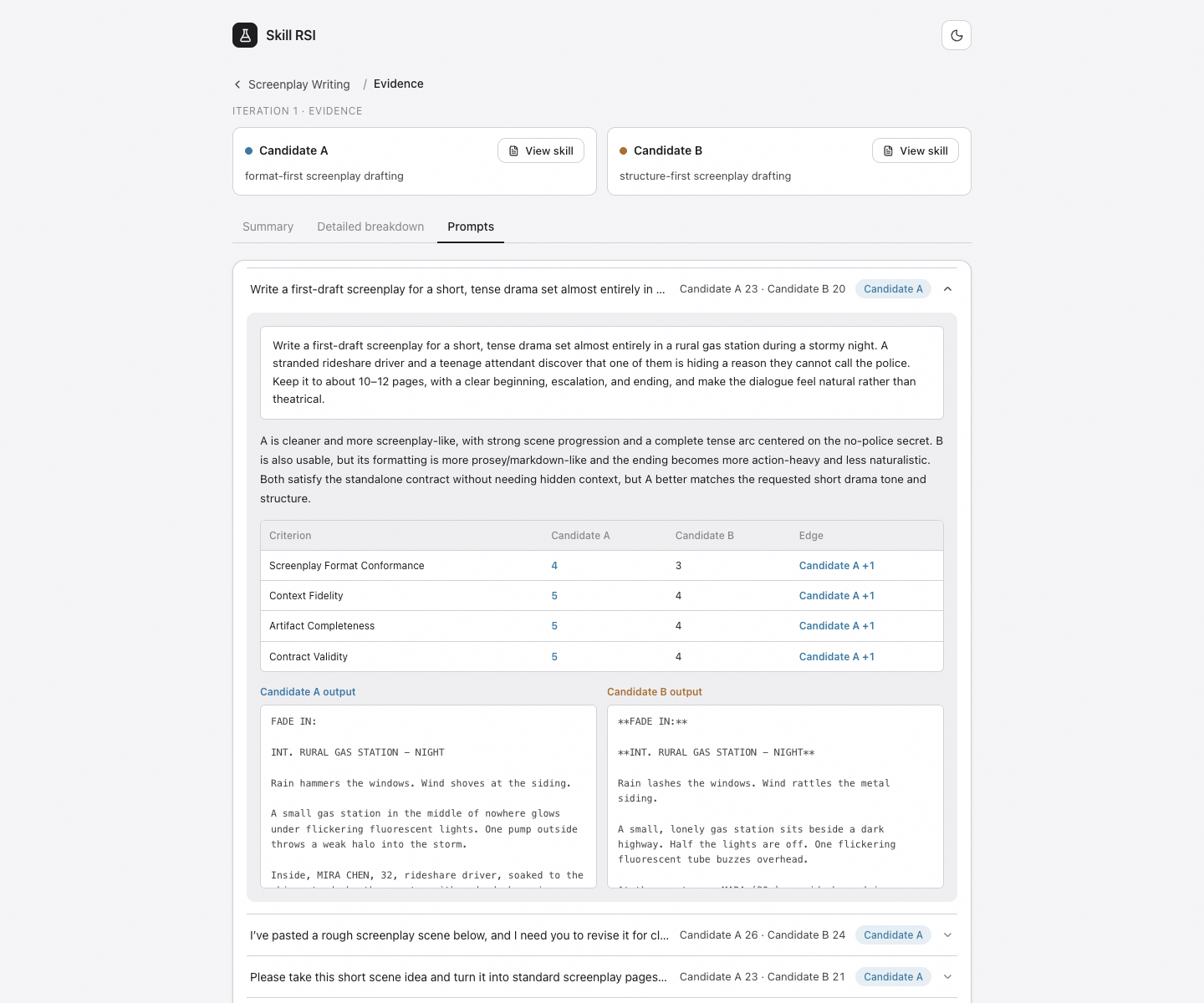
All state lives in plain files under .skill-rsi/projects/<name>/. API keys are not stored in project config. You bring your own OpenAI API key, run it locally, and decide how much autonomy you want: one manual loop, a batch of loops, scheduled runs, or based on Codex hooks.
Whether you’re writing skills for Claude, Codex, or your own agents, Skill RSI gives you a way to take an intention and improve it autonomously with real evidence instead of vibes. It researches the domain before writing. It treats the champion as the control. It makes focused changes. It evaluates against stable and exploratory prompts. It records what happened. It only keeps what earned its place.
That’s Skill RSI.
It’s free and open source at github.com/justinwetch/Skill-RSI. Plug in your API key and watch it build something good. Contributions, bug reports, weird use cases, failed runs, and any other issues are all welcome.